jeongmyeong zZZ,,
Bulkhead
Bulkhead?
MSA 환경에서 장애 상황을 겪다보면 복원력(resiliency), 고가용성(high availability) 과 함께 따라다니는 서킷 브레이커(circuit breaker), 벌크헤드(bulkhead) 등과 같은 키워드를 접하게 된다.
이 서킷 브레이커와 벌크헤드 모두 분산 시스템에서 발생할 수 있는 장애에 대응할 때 사용되는 시스템의 견고성과 내결함성을 향상시키기 위한 디자인 패턴이다.
서킷 브레이커는 서비스간 호출에서 성공, 실패를 감지해 실패가 일정 임계치를 넘으면 차단하는 회로 차단기의 모습이라면, 벌크헤드는 일정 서비스간 호출의 실패가 다른 서비스에 영향을 주지 않게 하는 모습에 가깝다.
선박 혹은 선체의 격벽(Bulkhead) 에서 유래된 이름이다. 선박은 여러 데크로 나누고 이를 완전히 격리하여 분리한다. 이때 격리하는 벽을 격벽 이라 한다. 선박이 각 데크를 분리하는 이유는 선박의 외부에 외상이 생겼을 때 각 데크를 완전히 격리하여 문제가 배 전체에 전파되지 않도록 하기 위함이다.
격벽에 대한 설명처럼 다른 리소스에 영향을 주지 않도록 문제 발생하는 리소스를 격리 하는 전략이다.
예를 들어 서비스 A 와 B 가 있고, A 가 B 서비스를 호출하는 구조일 때를 생각해보자.
어떤 이유로 B 서비스의 응답이 지연이 심해졌고, 이는 A 서비스의 성능에도 영향을 미친다. 이 상황이 지속된다면 A 의 스레드가 block 될 수 있다.
스레드의 부족으로 다른 서비스 (가령 C) 간의 호출, 또는 다른 기능을 하는데에 문제가 발생한다. 이런 문제를 대비해 B 를 위한 A 의 스레드를 일부 할당 해두어, 모든 스레드를 사용하지 않도록 방지한다.
Hystrix 와 Resilience4J
spring cloud 환경에서 이런 전략을 적용할 수 있는 대표적인 라이브러리들이 있는데, Netflix hystrix, Resilience4J, spring retry 가 그 예이다.
Spring Cloud 커뮤니티에서는 EOS(End Of Service) 된 Hystrix 의 대안으로 Resilience4J를 권고하고 있고, spring boot 3.x 로 버전을 마이그레이션 하면서 기존 사용하던 hystrix 에서 resilience4j 를 적용하게 되었다.
Resilience4J는 Hystrix의 동작원리에 착안해 만든 오픈소스라고 볼 수 있으며 요청 서비스와 제공 서비스 사이에 Resilience4J를 통해 통신하는것이 핵심 원리이다.
모든 요청이 Resilience4J를 통하므로, Circuit breaker, 격벽, 유량제어가 가능해진다.
아래는 기존 hystrix 와 Resilience4J 의 sample 이다. 보는 것 처럼 Resilience4J 에선 time limiter, rate limiter, bulkhead, circuit breaker, retry 등 다양한 설정이 지원된다.
## hystrix config set
#.. feign 과 같은 client 설정과 주로 함께 사용 됨
hystrix:
threadpool:
default:
coreSize: 50
serviceA:
coreSize: 100
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 10000
semaphore:
maxConcurrentRequests: 30
## resilience4j config set
resilience4j:
circuitbreaker:
configs:
default:
slidingWindowType: TIME_BASED
slidingWindowSize: 10 =
failureRateThreshold: 50
minimumNumberOfCalls: 20
waitDurationInOpenState: 30s
ignoreExceptions:
- feign.FeignException.FeignClientException
- ..
thread-pool-bulkhead:
configs:
default:
coreThreadPoolSize: 10
maxThreadPoolSize: 50
queueCapacity: 0
bulkhead:
configs:
..
timelimiter:
configs:
default:
timeoutDuration: 10s
instances:
service-a:
timeoutDuration: 30s
이중 벌크헤드에 대해서 좀 살펴보면, resilience4j 에선 2가지를 지원한다.
첫번째는 Semaphore로 동시 호출을 제한하는 SemaphoreBulkhead이며, 두번째는 고정된 thread pool을 이용하는 FixedThreadPoolBulkhead 방식입니다.
@Bulkhead(name = "abc", type = Bulkhead.Type.THREADPOOL) # type 인자
resilience4j:
bulkhead:
configs:
default:
# semaphore 방식에서는 아래의 설정들을 사용할 수 있다.
maxConcurrentCalls: 1
maxWaitDuration: 0
# thread pool 방식은 아래 설정들을 추가로 사용할 수 있다.
maxThreadPoolSize: 4
coreThreadPoolSize: 3
queueCapacity: 50
keepALiveDuration: 20
- maxConcurrentCalls ( default : 25 )
- 동시 호출 가능 수
- maxWaitDuration ( default : 0 )
- maxConcurrentCalls 를 다 소비했을 때 대기 시간
- maxThreadPoolSize ( default : Rntime.getRuntime().availableProcessors() )
- thread pool 최대 크기
- coreThreadPoolSize ( default : Runtime.getRuntime().availableProcessors() - 1 )
- thread pool 기본 크기
- queueCapacity ( default : 100 )
- 큐 사이즈
- keepAliveDuration ( default : 20 [ms] )
- thread pool 크기가 core 보다 커졌을 경우 증가한 thread 가 idle 될 때 새로운 작업을 기다리는 최대 시간
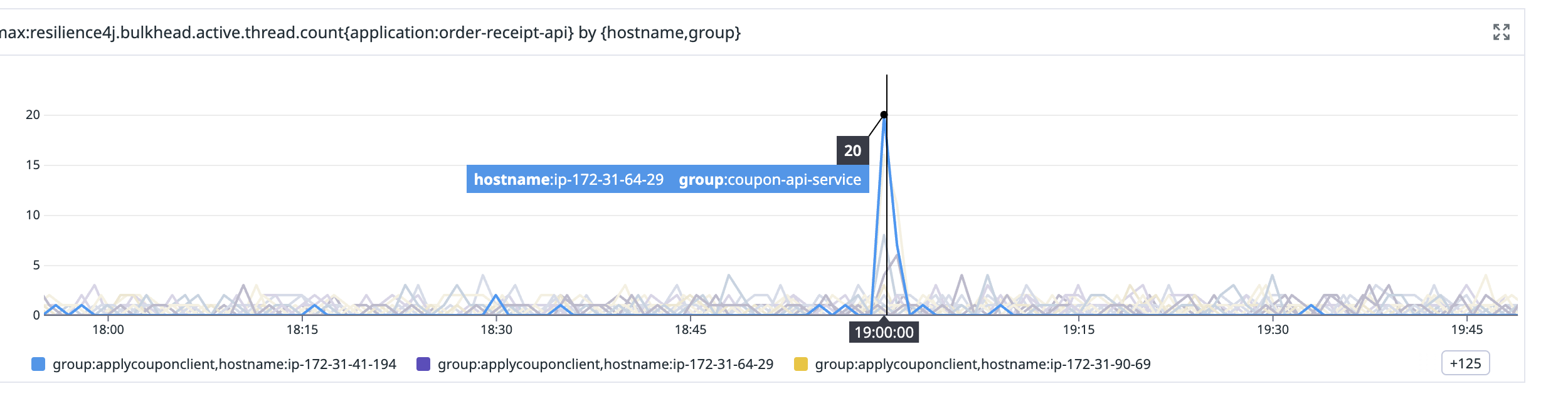 datadog 지표상 최대 thread 지표를 참고함
datadog 지표상 최대 thread 지표를 참고함
bulkhead thread 도 마찬가지지만, 스레드 수는 각 서비스별 적절한 선에 따라서 할당해주어야 한다.
스레드 자원이 적절하게 적용되지 않으면 컨텍스트 스위칭 비용, 메모리 비용 등이 과해 오히려 문제가 생길 수 있으니 말이다.
참고
- https://resilience4j.readme.io/docs/bulkhead
- https://dzone.com/articles/resilient-microservices-pattern-bulkhead-pattern
- https://sabarada.tistory.com/206