jeongmyeong zZZ,,
Debezium 을 활용한 CDC (Source Connector) 구현기
Debezium
Confluent사(카프카 지원 벤더)에서 개발한 Log-based Kafka Connect의 Source Connector 구현체이다.
MongoDB, MySQL, PostgreSQL, ORACLE, Db2, Cassandra 등의 저장소에 대한 connector 를 지원
MySQL 커넥터는 binlog에 액세스하기 위해 클라이언트 라이브러리를 사용합니다. (PostgreSQL 의 경우 logical replication stream 에서 읽음)
Rest API 형태의 커넥터 핸들링 과 Single message transformations (SMTs) 를 지원한다
smt?
- filter (CUD 중 일부 이벤트만 전달 하고 싶다)
- format transformation (방대한 메시지중 schema 정보외에 변경된 데이터 부분만 보고싶다)
- outbox event router (각 다른 aggregate type 별로 별도의 토픽으로) 등
Connector 구성
DB, Kafka cluster 는 구성되어 있다는 가정하에 링크 를 참고해 서비스를 구성한다
서비스가 정상적으로 구동 되었다면, 커넥터를 생성한다. body 에 포함된 config 및 config option 에 대한 설명도 위 링크에서 확인할 수 있다.
curl --request POST \
--url http://localhost:8083/connectors \
--header 'Content-Type: application/json' \
--data '{
"name": "커넥터 명",
"config": {
... // 링크 참조
}
}'
서비스를 기동해 커넥터를 생성하면, 상당한 양의 토픽이 생성 된다.
토픽이 생성되지 않거나, 오류가 발생한다면 auto topic creation 옵션을 활성화 해주면 된다.
대략적인 구조는 이런 모습이다.
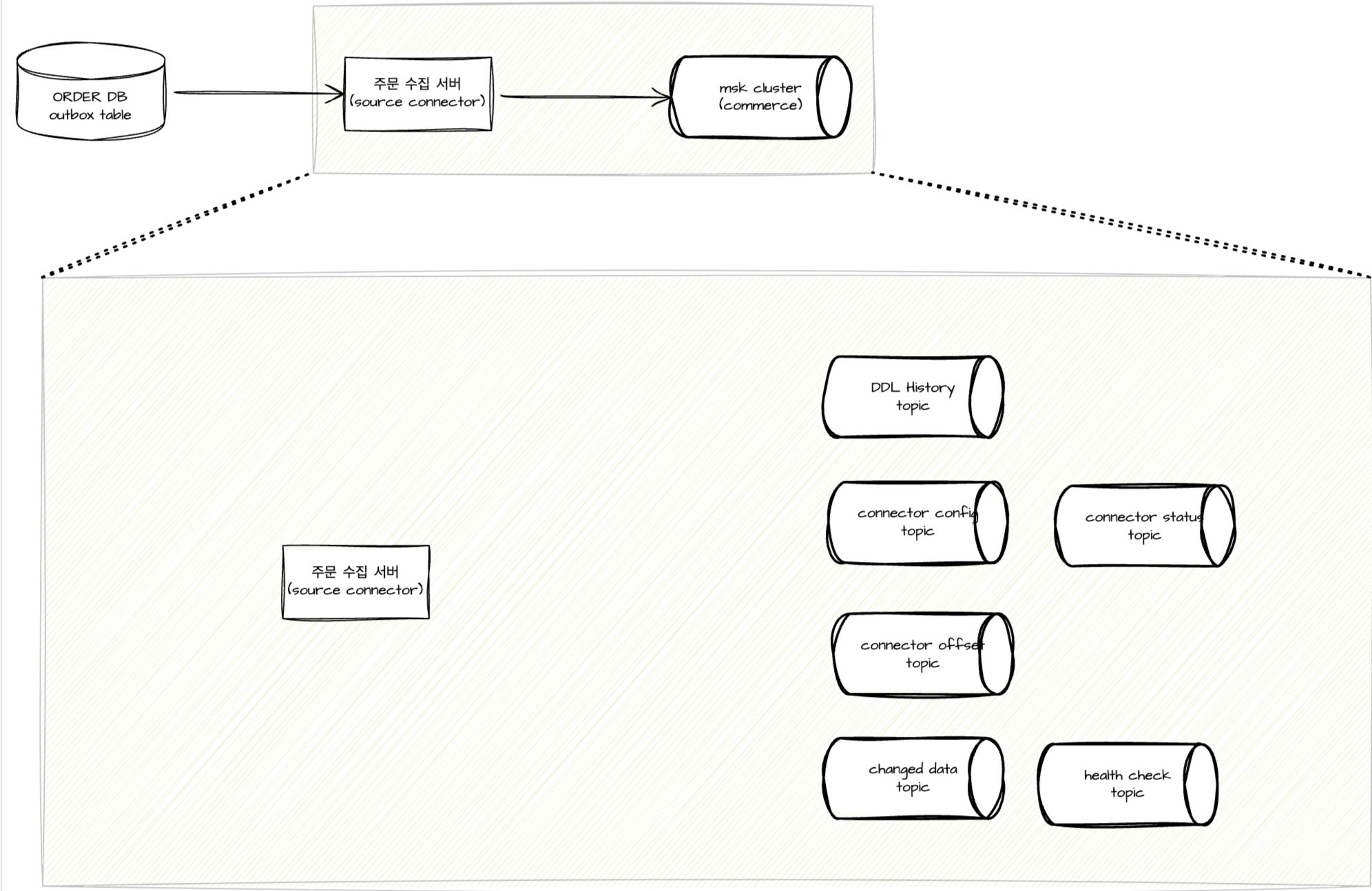 rds -> source connect -> kafka
rds -> source connect -> kafka
- 스키마 정보 토픽
- 캡쳐할 대상에 포함된 스키마에 대한 DDL 정보들을 발행한다
- 커넥터 컨피그 정보 토픽
- 위 Config 정보들을 담는다
- 커넥터 오프셋 정보 토픽
- 커넥터가 캡쳐한 binlog 들에 대한 정보를 담는다
- 데이터 캡쳐 정보 토픽
- connector 를 생성할 때 명시한 스키마의 실질적인 데이터 변경사항을 담는다
- 커넥터 상태 토픽
- 커넥터의 중지, 재개 등 상태들을 담는다
- 헬스체크용 토픽 (optional)
- 지정한 시간마다 헬스체크 정보를 담는다
- 필수는 아니지만, 토픽에 메시지가 일정기간동안 없는 경우 알림을 연동하거나 하면 유용하게 사용할 수 있다. (서비스 언헬시 상태는 이 외에 확인할 방법이 많아서 별도 구성하지 않음)
- ‘Heartbeat messages might help decrease the number of change events that need to be re-sent when a connector restarts’ 라는 안내가 있는데, connector의 재시작 시 다시 처리해야 하는 이벤트의 수를 줄이는 데 도움을 준다고 한다.
이 많은 토픽들에 데이터를 어떤 방식으로 발행 및 관리하는지를 보려면 snapshot 이란 개념을 알아야한다.
snapshot
snapshot 은 connector binlog offset snapshot 정보라고 이해해도 좋을 것 같다.
스냅샷을 저장하는 과정은 크게 아래와 같다. (snapshot.mode 와 snapshot.locking.mode 에 따라 조금씩 상이)
- table.include.list , table.exclude.list 참고해서 캡쳐할 테이블 결정
- snapshot 옵션에 따라 global read lock, table lock 등을 활용해 데이터 오염을 방지
- 현재 binlog의 position을 읽음.
- Connector가 읽어들일 테이블들의 스키마 정보를 가져옴.
- lock 해제
- DDL 변경 사항을 Schema change Topic에 기록.
- Connector가 대상 테이블들의 기존 레코드를 Topic에 전송
- Topic에 기록된 레코드 offset을 connect-offset 토픽에 기록
snapshot mode
- initial - 논리 서버 이름에 대한 오프셋이 기록되지 않은 경우에만 커넥터가 스냅샷을 실행합니다.
- initial_only - 논리 서버 이름에 대한 오프셋이 기록되지 않은 경우에만 스냅샷을 실행한 다음 중지합니다. 즉, 빈 로그에서 변경 이벤트를 읽지 않습니다.
- wheren_needed - 커넥터는 필요할 때마다 시동 시 스냅샷을 실행합니다. 즉, 오프셋을 사용할 수 없거나 이전에 기록된 오프셋이 서버에서 사용할 수 없는 binlog 위치 또는 GTID를 지정할 때입니다.
- never - 커넥터는 스냅샷을 절대 사용하지 않습니다. 논리적 서버 이름으로 처음 시작할 때, 커넥터는 binlog의 처음부터 읽습니다. 이 동작을 주의하여 구성하십시오. binlog가 데이터베이스의 전체 이력을 포함하도록 보장되어야만 유효합니다.
- schema_only - 데이터가 아닌 스키마의 스냅샷을 커넥터에서 실행합니다. 이 설정은 데이터의 일관된 스냅샷을 포함하기 위해 항목이 필요하지 않고 커넥터가 시작된 이후의 변경 사항만 있으면 될 때 유용합니다.
- schema_only_recovery - 이미 변경 사항을 캡처하고 있는 커넥터에 대한 복구 설정입니다. 커넥터를 다시 시작할 때 이 설정을 사용하면 손상되거나 손실된 데이터베이스 스키마 기록 항목을 복구할 수 있습니다. 예기치 않게 증가하고 있는 데이터베이스 스키마 기록 항목을 “정리”하도록 주기적으로 설정할 수 있습니다. 데이터베이스 스키마 기록 항목에는 무한 리텐션이 필요합니다.
snapshot locking mode
- minimal - 커넥터는 데이터베이스 스키마와 다른 메타데이터를 읽는 스냅샷의 초기 부분에 대해서만 글로벌 읽기 잠금을 유지합니다. 스냅샷의 나머지 작업은 각 테이블에서 모든 행을 선택하는 것입니다. 커넥터는 REPATEBLE READ 트랜잭션을 사용하여 일관된 방식으로 이 작업을 수행할 수 있습니다. 글로벌 읽기 잠금이 더 이상 유지되지 않고 다른 MySQL 클라이언트가 데이터베이스를 업데이트하는 경우에도 마찬가지입니다.
- minimal_percona - Connector가 데이터베이스 스키마 및 기타 메타데이터를 읽는 스냅샷의 초기 부분에 대해서만 글로벌 백업 잠금을 유지합니다. 스냅샷의 나머지 작업은 각 테이블에서 모든 행을 선택하는 것입니다. Connector는 REPATEBLE READ 트랜잭션을 사용하여 일관된 방식으로 이 작업을 수행할 수 있습니다. 글로벌 백업 잠금이 더 이상 유지되지 않고 다른 MySQL 클라이언트가 데이터베이스를 업데이트하는 경우에도 마찬가지입니다. 이 모드는 테이블을 디스크에 플러시하지 않으며, 오래 실행되는 읽기로 인해 차단되지 않으며 Percona Server에서만 사용할 수 있습니다.
- extended - 스냅샷 기간 동안의 모든 쓰기를 차단합니다. MySQL이 REPATEBLE READ 의미론에서 제외하는 작업을 제출하는 클라이언트가 있는 경우 이 설정을 사용합니다.
- none - 스냅샷 중에 커넥터가 테이블 잠금을 획득할 수 없도록 합니다. 이 설정은 모든 스냅샷 모드에서 허용되지만 스냅샷이 실행되는 동안 스키마 변경이 발생하지 않는 경우에만 사용해도 안전합니다. MyISAM 엔진으로 정의된 테이블의 경우 MyISAM이 테이블 잠금을 획득할 때 이 속성이 설정되었음에도 불구하고 테이블이 여전히 잠깁니다. 이 동작은 행 레벨 잠금을 획득하는 InnoDB 엔진과 다릅니다.
snapshot mode 에 대해서는 밑 문단에서 이어집니다.
구성 중 트러블 슈팅
- 서비스가 갑자기 먹통이예요
커넥터를 처음 등록 했을 때 가장 먼저 마주칠 수 있는 문제가 있는데, 바로 캡쳐 대상 스키마와 관련 된 서비스가 정상적으로 동작하지 않는 것이다.
위 snapshot 생성 및 관리에 대해 짧게 얘기했는데, 이 snapshot mode 의 default 설정은 global read lock 을 잡는 옵션이다.
스냅샷 생성 중 데이터의 오염이나 누락 방지를 위해 높은 단계의 잠금을 전역 설정하고 snapshot 을 생성하게 되는데, 이 대상 테이블에 데이터량이 많은 경우 이 데이터를 읽어 메시지를 발행하기까지 상당한 시간 서비스에 지장이 있다.
물론 커넥터의 처리량도 많아져 커넥터 서비스에도 부하가 심해진다.
각 서비스 특성에 맞게 (누락에 대한 민감성, 신규 스키마 등등 많은 상황) 설정하면 되며, 이 글에선 기존에 데이터가 많이 쌓여있는 기존 테이블의 데이터를 캡처하기 때문에 snapshot mode 는 schema_only, locking mode 는 none 으로 설정했다.
- 아무것도 하지 않았는데 조회(Read) 에 대한 메시지가 다량 발행돼요
1번과 비슷하게 커넥터가 처음 실행될 때 CUD 가 아닌 R (조회) 액션에 대한 메시지가 다량 발행될 수 있다.
Debezium Source Connector의 snapshot.mode는 웬만해선 schema_only로 설정해 주는게 좋다. schema_only로 설정하면 Debezium은 새로 들어온 Change Event부터 메시지를 생성하게 된다.
또는 커넥터 최초 구동시 읽어드린 스냅샷 데이터입니다. 같은 이유로 대용량 테이블의 토픽 메시지를 조회할 때는 — from -beginning 옵션을 제거하면된다
- 빈로그를 읽었으나, 메시지가 정상적으로 발행되지 않아요
2024-03-19 14:45:00 2024-03-19 05:45:00,986 WARN [Producer clientId=connector-producer-order-cdc-test-002-0] Error while fetching metadata with correlation id 114 : {ORDERTEST.ORDER.t_est=UNKNOWN_TOPIC_OR_PARTITION} [org.apache.kafka.clients.NetworkClient]
이런 로그를 만났다면 토픽에 대해 문제가 있을 가능성이 높다. 토픽을 수동으로 생성했을 경우, 토픽 명에 대한 rule 에 맞지 않게 생성 되었을 가능성이 높다.
- 토픽과 파티션에 문제가 없는데도 메시지가 정상적으로 발행되지 않아요
2024-03-25 08:30:20 2024-03-24 23:30:20,186 ERROR || [Worker clientId=connect-1, groupId=test-cdc] Uncaught exception in herder work thread, exiting: [org.apache.kafka.connect.runtime.distributed.DistributedHerder] 2024-03-25 08:30:20 org.apache.kafka.common.config.ConfigException: Topic ‘my-connect-statuses’ supplied via the ‘status.storage.topic’ property is required to have ‘cleanup.policy=compact’ to guarantee consistency and durability of connector and task statuses, but found the topic currently has ‘cleanup.policy=delete’. Continuing would likely result in eventually losing connector and task statuses and problems restarting this Connect cluster in the future. Change the ‘status.storage.topic’ property in the Connect worker configurations to use a topic with ‘cleanup.policy=compact’.
와 같은 오류도 마주한 적이 있다면, 위 2번과 같은 원인일 경우가 높다. 토픽을 수동으로 생성하는 경우 cleanup.policy 가 delete 인데, 설정 관련한 토픽들은 compact 옵션을 필요로 하니 잘 확인해야한다.
토픽 자동 생성 옵션을 제거한 뒤 토픽을 직접 생성하는 경우 config 성 토픽들은 cleanup.policy 를 잘 설정해야한다.
커넥터들은 각 성격에 맞는 토픽의 메시지를 읽어 마지막 저장된 설정 정보를 가져와 재기동 등의 상황에 활용하게 된다.
- delete
- retention 에 맞게 오래 된 메시지가 토픽에서 사라지는 방식.
- 이 경우 메시지가 사라져 retention 기간 이후 서비스를 재기동하거나 배포할 때 문제가 생긴다. 이를 커넥터가 동작시에 자체적으로 판단해서 오류를 반환
- compact
- Kafka의 특수한 정책 중 하나로, 메시지의 키(Key)를 기반으로 중복을 제거하는 방식으로 메시지를 보존하는 방식
- 주로 상태 정보나 참조 데이터와 같은 데이터에 유용하며, 키-값 저장소의 역할을 수행할 수 있음
- Connector 기동시 원하는 부분부터 데이터를 읽지 못해요
오래된 binlog 가 Purge 되었을 가능성이 높다.
- Connector는 자신이 읽어서 Kafka로 보낸 offset 정보를 binlog명과 binlog position으로 connect-offsets 토픽이 기록
- 만약 오랫동안 Connector를 기동하지 않는다면, binlog가 mysql expire log 기간 이상 저장되어 있을 경우 삭제될 수 있음. 이때 Connector는 connect-offsets에 기록된 binlog를 binlog 디렉토리에서 찾지 못해서 기동을 할 수 없음.
- 이 경우 새롭게 Connector를 생성하거나 connect-offsets의 offsets를 재 설정 필요. 또한 오랫동안 정지할 Connector는 미리 삭제하는 것이 좋음
- 서비스가 중단 되었을 때 재기동 이후 동일 메시지가 중복 발행돼요
링크 를 보면 항상 멱등에 대한 고려가 필요하다고 가이드가 되어 있다.
Why must consuming applications expect duplicate events? .. When all systems are running nominally or when some or all of the systems are gracefully shut down, then consuming applications can expect to see every event exactly one time. However, when things go wrong it is always possible for consuming applications to see events at least once. When the Debezium’s systems crash, they are not always able to record their last position/offset. When they are restarted, they recover by starting where were last known to have been, and thus the consuming application will always see every event but may likely see at least some messages duplicated during recovery. Additionally, network failures may cause the Debezium connectors to not receive confirmation of writes, resulting in the same event being recorded one or more times (until confirmation is received).
항상 컨슈머는 중복된 이벤트를 소비할 수 있다는 점을 알고 있어야된다
커넥터가 항상 offset 을 기록할 수 있는 상태가 아닐 수 있고, 네트워크 이슈등으로 썼다는 이벤트를 제대로 기록하지 못했다면 재발행 될 수 있다
- heartbeat topic 은 토픽명 커스터마이즈가 안돼요
topic.heartbeat.prefix 옵션은 제공하지만 DB서버명.테이블명 과 같은 형태의 네이밍 룰을 커스터마이즈 하기가 어렵다.
가이드문서 를 보면 Topic name strategy 를 custom 하게 구현할 수 있는 기능을 제공한다고 한다.
config 설정만으론 어렵고 별도의 Plugin 을 생성해 구현해야한다.
참고 링크들
- https://debezium.io/documentation/reference/1.8/connectors/mysql.html
- https://hoing.io/archives/5286
- https://velog.io/@jm94318/3%ED%8E%B8-MSA-%EC%9D%B4%EB%B2%A4%ED%8A%B8-%EB%B0%9C%ED%96%89-Debezium-Transformations
- https://techblog.pet-friends.co.kr/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%8B%B1%ED%81%AC%EB%A5%BC-%EC%9C%84%ED%95%9C-msk-connect-%EB%8F%84%EC%9E%85-feat-cdc-%EB%BD%80%EA%B0%9C%EA%B8%B0-b1f341b495f
- https://www.iamninad.com/posts/docker-compose-for-your-next-debezium-and-postgres-project/